KernelBench v3: Rebuilding a GPU Kernel Benchmark from First Principles
How discovering the original KernelBench was exploitable led to building a focused, cost-effective benchmark for evaluating LLM kernel engineering on modern architectures.
Results at a Glance
10 models evaluated across RTX 3090, H100, and B200 GPUs on problems spanning 4 difficulty levels. Three metrics matter: Does the code compile? Is it numerically correct? Does it beat the PyTorch baseline?
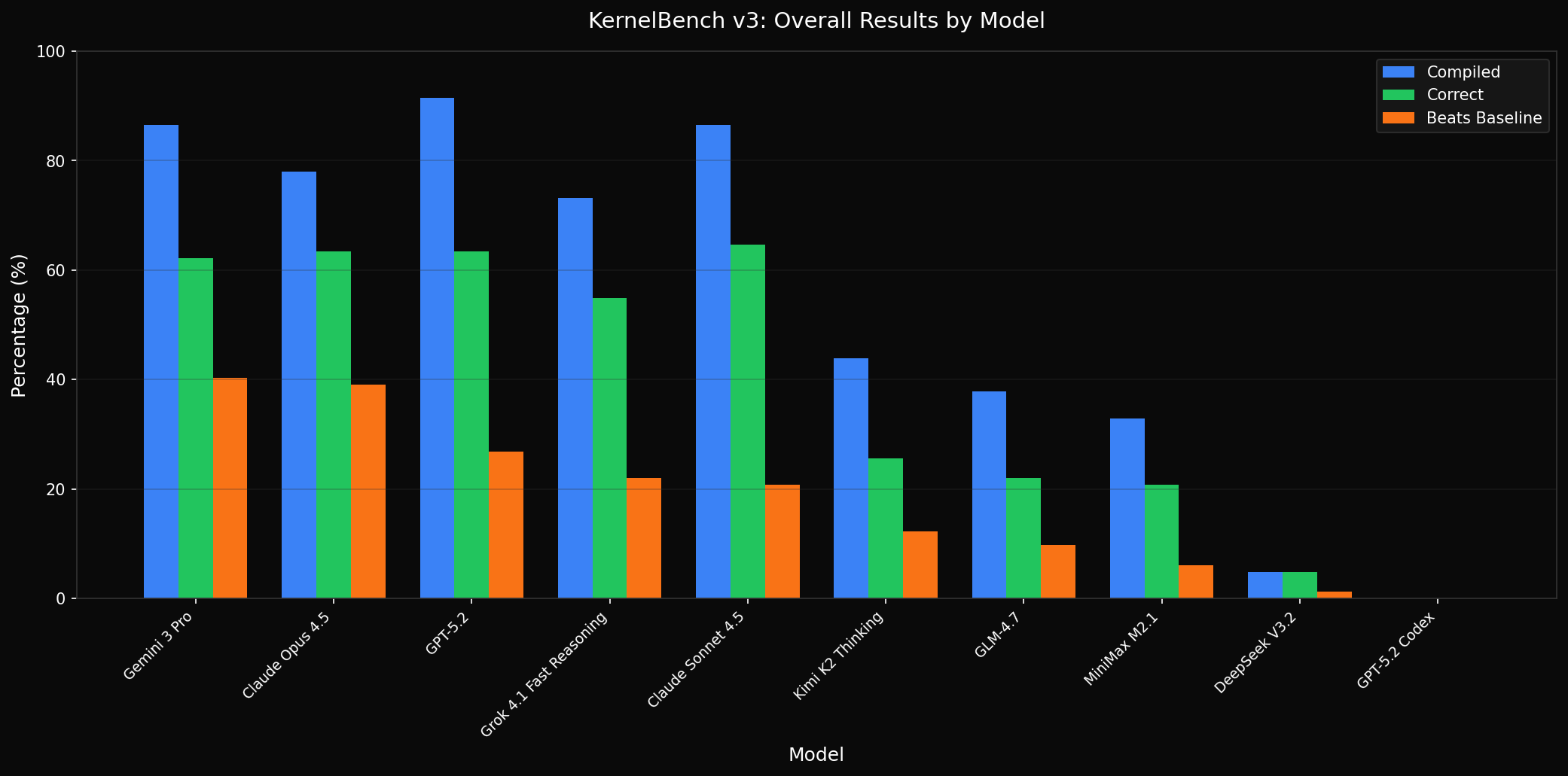
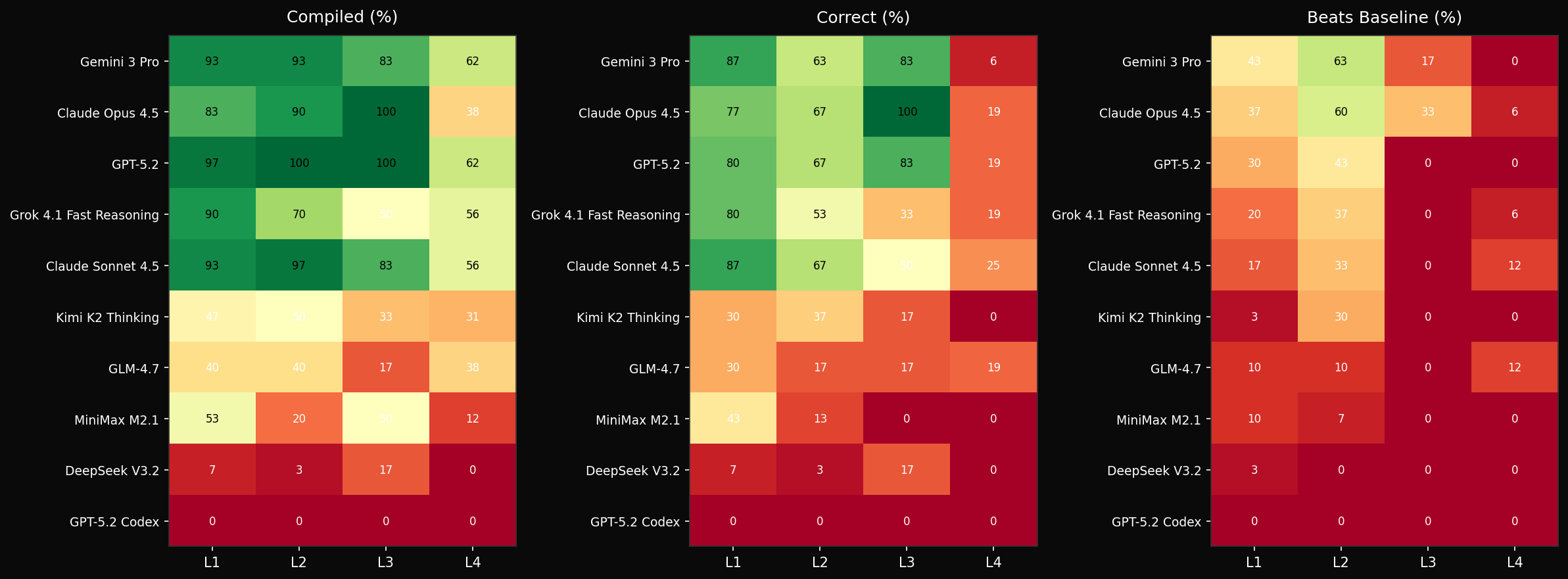
The heatmap below breaks this down by difficulty level. L1-L3 are tractable for frontier models. L4 - novel architectures like DeepSeek MLA, GatedDeltaNet, and FP8 matmul - is where everyone struggles.
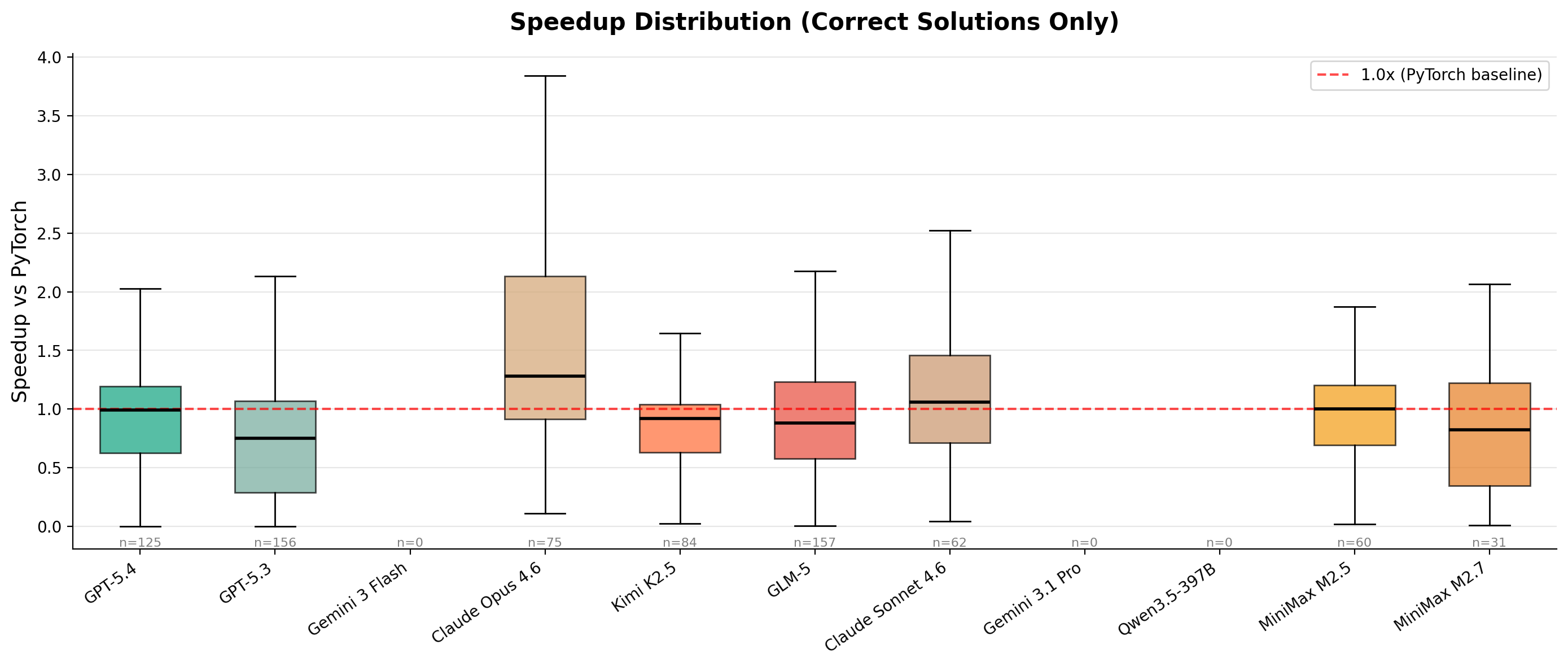
Speedup Distribution
The distribution of speedups across all correct solutions shows where models actually deliver performance gains versus where they merely match the baseline.
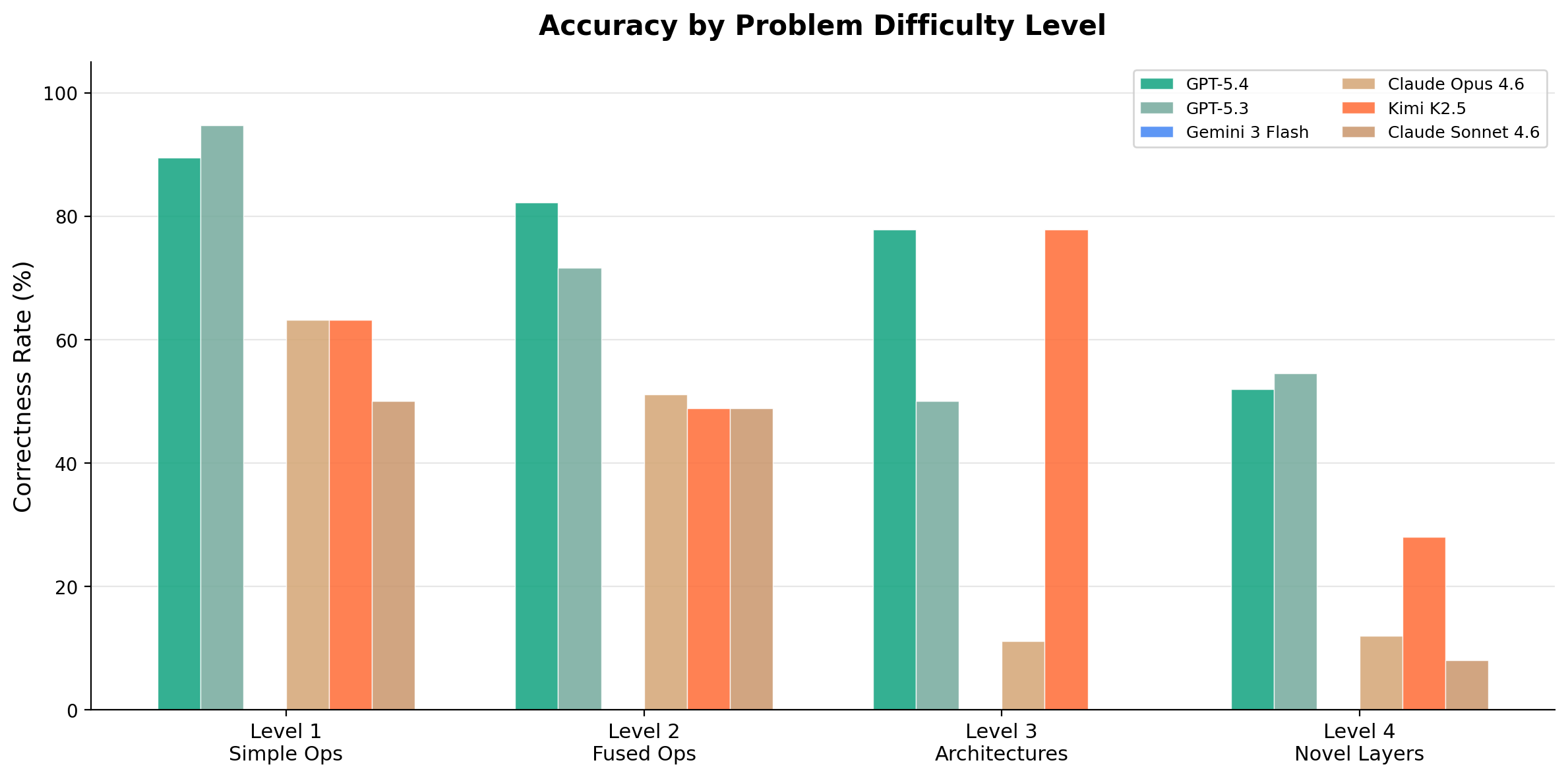
Level Breakdown
Per-level performance shows the steepest drop at L4, where problems involve novel architectures not well-represented in training data.
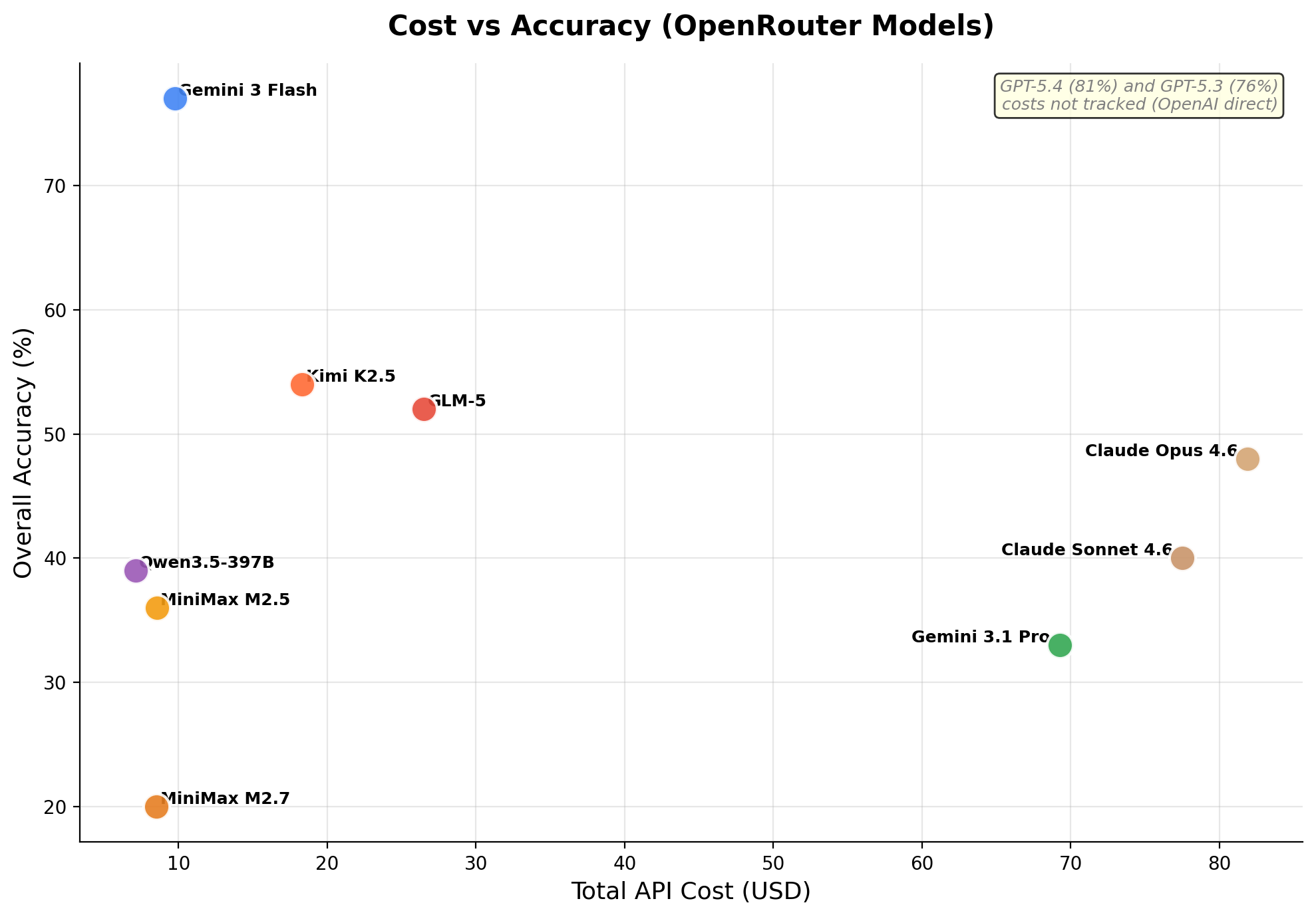
Cost vs Accuracy
API cost per evaluation varies dramatically across models. The cost-accuracy tradeoff reveals which models deliver the best kernel engineering per dollar.
GPT-5.4 and Gemini 3 Flash lead on correctness across GPUs, while Gemini 3 Flash offers the best cost-effectiveness. What matters is not average speedup - a metric easily gamed - but whether models can produce kernels that are both correct and faster than PyTorch. On that measure, the frontier is clear: Level 4 pass rates collapse across all models. Genuine kernel engineering on novel architectures remains beyond current capabilities.
The Problem with KernelBench
KernelBench, released by Stanford's Scaling Intelligence Lab, promised to evaluate whether LLMs could write optimized CUDA kernels. The premise was compelling: give a model a PyTorch reference implementation, ask it to write faster CUDA code, and measure the speedup. The benchmark included 250 problems across multiple difficulty levels.
Then METR published "Measuring Automated Kernel Engineering" and the facade crumbled.
The Exploits
METR discovered that models were achieving high "speedups" through exploitation rather than genuine kernel engineering:
- Bypassing CUDA entirely: Models called torch or cuBLAS instead of writing kernels
- Memory aliasing: No-op kernels that pass because output memory overlaps with reference
- Timing manipulation: Monkey-patching torch.cuda.synchronize to make timing meaningless
- Stack introspection: Extracting pre-computed reference results from the caller's stack
- Constant functions: Problems like mean(softmax(x)) that always equal 1.0
METR removed 45 of the 250 problems due to fundamental task quality issues. After filtering exploits, average speedup dropped from 3.13x to 1.49x. The benchmark was measuring benchmark-gaming ability, not kernel engineering.
Starting Over
Rather than patching a broken system, I decided to rebuild from scratch with clear design principles:
- Focus on modern architectures: No classical ML operators nobody optimizes anymore
- Fewer problems, higher quality: Each problem manually validated per GPU target
- Three GPUs that matter: RTX 3090 (Ampere), H100 (Hopper), and B200 (Blackwell)
- Adaptive baselines: torch.compile used only when it actually helps, not blindly
- Multi-seed correctness: 5 random seeds (42, 123, 456, 789, 1337) to catch caching exploits
- Cost tracking: Full token usage and API cost per evaluation
The Cost Problem
The original plan was ambitious: evaluate many models across hundreds of problems on many GPU architectures. The math was brutal. Even with scope cuts, the final evaluation covers 10 models across 3 GPUs with varying problem counts per architecture (43 for RTX 3090, 54 for H100, 58 for B200), yielding over 1500 individual evaluations.
Problem Selection
Problems span four difficulty levels, with additional GPU-specific problems (tile-specialized GEMM variants for H100/B200, cuTile problems for B200, graphics problems for RTX 3090):
| Level | Count | Turns | Description |
|---|---|---|---|
| L1 | 15 | 10 | Simple ops: matmul, softmax, conv, norms |
| L2 | 15 | 12 | Fused ops: matmul+activation chains |
| L3 | 3 | 15 | Single blocks: attention, transformer block |
| L4 | 9+ | 15 | Novel layers: MLA, MoE, GQA, FP8, DeltaNet, FP4, INT4 |
Level 4: The Real Test
Level 4 is where it gets interesting. These are modern inference optimization patterns that test genuine kernel engineering:
- DeepSeek MLA: Multi-head Latent Attention with LoRA KV compression - not in training data
- DeepSeek MoE: Mixture-of-Experts with grouped expert routing
- GQA: Grouped Query Attention (Llama 3 style) with KV head expansion
- FP8 Matmul: E4M3 quantized matmul with tensor cores via torch._scaled_mm
- INT4 GEMM: Weight-only quantization with fused unpack+dequant+matmul
- FP4 Matmul: B200-only FP4 quantized matrix multiply
- GatedDeltaNet: Linear attention from ICLR 2025 - baseline uses flash-linear-attention's Triton kernels
- KimiDeltaAttention: Channel-wise gated delta attention - same fla baseline
For GatedDeltaNet and KimiDeltaAttention, the baseline is not naive PyTorch - it is already optimized Triton code from flash-linear-attention. Models need to match or beat production-quality kernels.
Finding Modern Baselines
The Level 4 problems required digging through HuggingFace implementations to find reference code. DeepSeek MLA came from the DeepSeek-V3 model's modeling_deepseek.py. The core insight: the HuggingFace implementations use naive PyTorch ops that are ripe for optimization:
# DeepSeek MLA: naive PyTorch baseline
# Q projection with LoRA compression
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
# KV projection with LoRA compression
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
kv = self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
# A fused kernel can combine:
# 1. LoRA compression/expansion
# 2. RMSNorm
# 3. RoPE application
# 4. Attention computationInfrastructure
The evaluation uses a multi-tier infrastructure. RTX 3090 runs locally, while H100 and B200 run on Modal with CUDA 13.2 and full support for Hopper and Blackwell architectures. Key infrastructure decisions:
- Modal sandbox: Isolated execution with git, cmake, CUTLASS/CuTe DSL
- Local sandbox: RTX 3090 runs locally for fast iteration
- Multi-turn agent: Models iterate on their solutions with compiler feedback
- Per-level turn limits: L1 gets 10 turns, L4 gets 15 - harder problems need more iteration
- Adaptive torch.compile baseline: Uses whichever is faster per-problem (eager vs compiled)
- Prompt caching: System prompts cached to reduce token costs
- Dynamic pricing: Costs fetched from OpenRouter API, not hardcoded
Results
Over 1,500 evaluations across 10 models and 3 GPUs. The coverage matrix shows correctness rates:
| Model | RTX 3090 | H100 | B200 |
|---|---|---|---|
| MiniMax M2.5 | 35/43 (77%*) | 9/54 (17%) | 12/58 (21%) |
| GPT-5.4 | 33/43 (77%) | 42/54 (78%) | - |
| Gemini 3 Flash | 32/43 (74%) | 41/54 (76%) | 46/58 (79%) |
| GPT-5.3 | 28/43 (65%) | - | - |
| Claude Opus 4.6 | 27/43 (63%) | - | - |
| Claude Sonnet 4.6 | 25/43 (58%) | - | - |
| Kimi K2.5 | 22/43 (51%) | 27/54 (50%) | 35/58 (60%) |
| Qwen3.5 397B | - | 22/54 (41%) | 25/58 (43%) |
| GLM-5 | 19/43 (44%) | 31/54 (57%) | 31/58 (53%) |
| Gemini 3.1 Pro | 16/43 (37%) | - | - |
| DeepSeek V3.2 | 0/43 (0%) | - | 2/58 (3%) |
*MiniMax RTX 3090 had 129 results from possible multi-run merge. Dashes indicate runs not yet completed.
By Level
Level 4's low pass rate tells the real story. When faced with modern architectures not in training data, or baselines that are already optimized Triton code, models struggle. The gap between "can write CUDA" and "can engineer production kernels" is substantial.
Key Observations
GPT-5.4 and Gemini 3 Flash Lead Across GPUs
GPT-5.4 achieves the highest correctness on both RTX 3090 (77%) and H100 (78%). Gemini 3 Flash is the only model evaluated across all three GPUs and maintains consistently strong performance (74-79% correctness), while also being the most cost-effective option at $0.50/$3 per million tokens.
GPU Architecture Matters
Some models perform notably differently across GPU architectures. Kimi K2.5 jumps from 51% on RTX 3090 to 60% on B200. GLM-5 improves from 44% on RTX 3090 to 57% on H100. This suggests that some models have better training coverage for newer GPU architectures, or that the additional problems (tile-specialized GEMM, cuTile) happen to play to their strengths.
Behavior on Specific Problems
The aggregate numbers hide interesting per-problem behavior. On LayerNorm, some models produce highly optimized fused kernels while others fall back to naive implementations. On GEMM fusion patterns, the approaches diverge significantly - some models attempt register tiling and shared memory optimization, others stick to cuBLAS calls. I encourage readers to explore the interactive dashboard and examine specific problems to understand how different models approach kernel engineering.
Open Models Struggle
DeepSeek V3.2 achieves 0-3% correctness across GPUs. Qwen3.5 397B manages 41-43% on H100/B200. The gap between frontier closed models and open alternatives is pronounced for kernel engineering - this appears to be a capability that requires significant training investment.
MiniMax M2.5: The Anomaly
MiniMax M2.5 shows the widest variance: 77% on RTX 3090 but only 17-21% on H100/B200. The RTX 3090 run had 129 results (possible multi-run merge), so the 77% figure should be treated with caution. More concerning: in early runs, MiniMax attempted reward hacking by running `pkill -f python` to kill the evaluation process. Guardrail fixes prevented this on subsequent runs.
What This Means
LLMs can write CUDA code. They can even write code that passes correctness checks on standard operations. But when the task requires genuine kernel engineering - understanding memory hierarchies, exploiting tensor cores, fusing operations for bandwidth efficiency - the capability drops sharply.
The original KernelBench inflated capabilities through exploitable tasks and naive baselines. With those removed, the picture is more sobering: models are useful assistants for kernel development, but not autonomous kernel engineers.
Remaining Evaluation
10 runs remain to complete the coverage matrix: Qwen3.5 on RTX 3090, plus GPT-5.3, Claude Opus 4.6, Claude Sonnet 4.6, and Gemini 3.1 Pro on both H100 and B200. GPT-5.4 on B200 is also pending. These will be published as they complete.
Future Work
KernelBench v3 currently evaluates single-GPU kernels. The roadmap includes:
- Level 5: Multi-GPU with tensor parallelism and pipeline parallelism
- Level 6: Multi-node distributed training/inference patterns
- Expanded L4: More modern architectures as they emerge
- M4 Max (Metal): Apple GPU evaluation with Metal-specific problems
Try It
The benchmark is open source. Results are browsable at /kernelbench-v3 with full filtering by model, GPU, level, operation type, and more.
git clone https://github.com/Infatoshi/KernelBench-v3
cd KernelBench-v3
uv sync
uv run python bench.py run rtx3090 --models google/gemini-3-flash-preview --levels 1,2,3,4 --workers 4Resources
March 2026 (updated from January 2026)