Dendrite: 133x Faster Battery Simulation with Hand-Tuned CUDA
A development log of optimizing battery simulation kernels from scratch. Starting with naive GPU code that was slower than CPU, ending at 89% of theoretical peak bandwidth.
The Starting Point
Battery simulation involves solving coupled PDEs: diffusion of lithium in electrode particles, Butler-Volmer electrochemical kinetics at surfaces, and heat transport. The standard tool is PyBaMM - excellent physics, clean API, but CPU-only.
I wanted to know how fast these kernels could actually run on a GPU. The physics is embarrassingly parallel - thousands of electrode particles, each independent. Should be a perfect GPU workload.
Attempt 1: CuPy (Naive GPU)
First attempt: take vectorized NumPy code, swap the import for CuPy.
import cupy as cp # instead of numpy as np
# Spherical diffusion stencil
c_new[:, 1:-1] = c[:, 1:-1] + alpha * (
r_plus * (c[:, 2:] - c[:, 1:-1]) -
r_minus * (c[:, :-2] - c[:, 1:-1])
)Result: CuPy was 30% slower than NumPy.
This was surprising. Each array slice and arithmetic operation launches a separate CUDA kernel. That single line launches 6+ kernels, each with ~3 microseconds of overhead. For 10K particles with 32 points each, the data is too small to amortize the launch cost.
This is why the battery community hasn't adopted GPU. Naive ports don't help - they make things worse.
Attempt 2: Custom CUDA Kernel
The fix is kernel fusion. One kernel that does the entire stencil update:
__global__ void diffusion_2d_kernel(
const float* __restrict__ c_in,
float* __restrict__ c_out,
float rx, float ry, int nx, int ny)
{
int gx = blockIdx.x * blockDim.x + threadIdx.x;
int gy = blockIdx.y * blockDim.y + threadIdx.y;
int gid = gy * nx + gx;
if (gx > 0 && gx < nx-1 && gy > 0 && gy < ny-1) {
float c = c_in[gid];
float left = c_in[gid - 1];
float right = c_in[gid + 1];
float top = c_in[gid - nx];
float bottom = c_in[gid + nx];
c_out[gid] = c + rx*(left - 2.0f*c + right)
+ ry*(top - 2.0f*c + bottom);
}
}First benchmark: 787 GB/s on a 4096x4096 grid. RTX 3090 has 936 GB/s theoretical peak, so that's 84%. Not bad for a first attempt.
The Occupancy Trap
Standard CUDA advice: maximize occupancy. Run as many threads as possible to hide memory latency. I started with 32x16 blocks (512 threads).
Then I tried smaller blocks, expecting worse performance:
| Block Size | Threads | Occupancy | Bandwidth |
|---|---|---|---|
| 32x16 | 512 | 33% | 787 GB/s |
| 32x8 | 256 | 17% | 815 GB/s |
| 32x4 | 128 | 8% | 836 GB/s |
8% occupancy beat 33% occupancy. This is counter-intuitive but makes sense for memory-bound stencils: fewer active warps means more L2 cache per warp. Stencil neighbors that would have been evicted stay resident. Less DRAM traffic, higher effective bandwidth.
This finding alone took the 2D diffusion kernel from 84% to 89% of peak.
Spherical Diffusion: From 36% to 85%
The spherical diffusion kernel (for electrode particles) was initially much slower - only 36% of peak. The problem: I was using shared memory with __syncthreads() for a 32-element array.
// Original: shared memory approach
__shared__ float s_c[32];
s_c[lane] = c_val;
__syncthreads(); // Barrier!
float c_right = s_c[lane + 1];
__syncthreads(); // Another barrier!
c[idx] = c_new;32 elements is exactly one warp. Warps execute in lockstep - they don't need explicit synchronization. The fix: warp shuffle instructions.
// Optimized: warp shuffles, no sync needed
float c_left = __shfl_up_sync(0xFFFFFFFF, c_val, 1);
float c_right = __shfl_down_sync(0xFFFFFFFF, c_val, 1);Combined with processing 8 particles per block (8 warps = 256 threads) instead of 1 particle per block:
| Version | Bandwidth | Peak % |
|---|---|---|
| Shared memory + sync | 340 GB/s | 36% |
| Warp shuffle | 799 GB/s | 85% |
A 2.4x speedup from removing unnecessary synchronization.
What Didn't Work
Not every optimization helps. Things I tried that made no difference (or made things worse):
- Shared memory tiling - Already at 85%+ peak, tiling adds overhead without reducing DRAM traffic
- FP16 - Half2 vectorization breaks at stencil boundaries. FP16 diffusion hit only 64% of peak vs 89% for FP32
- Register tiling - Only helps compute-bound kernels. These are memory-bound
- Async copy (cp.async) - Minimal compute to overlap with memory
- Texture memory - L2 cache already handles neighbor reuse efficiently
When you're at 85-89% of peak bandwidth, most "optimizations" just add overhead.
Final Benchmark Results
Task: 10,000 electrode particles, 32 radial points, 288 timesteps (100 seconds of simulation).
| Method | Time | vs Dendrite |
|---|---|---|
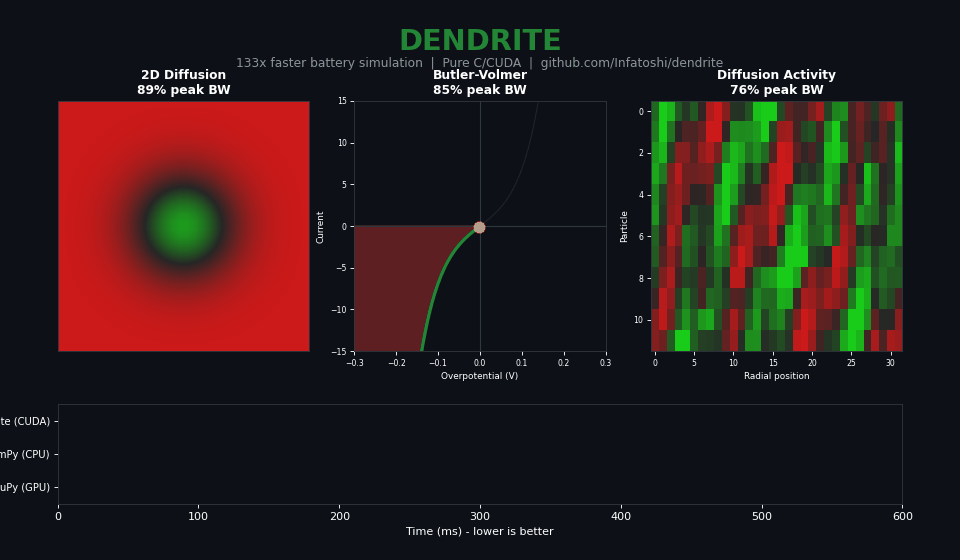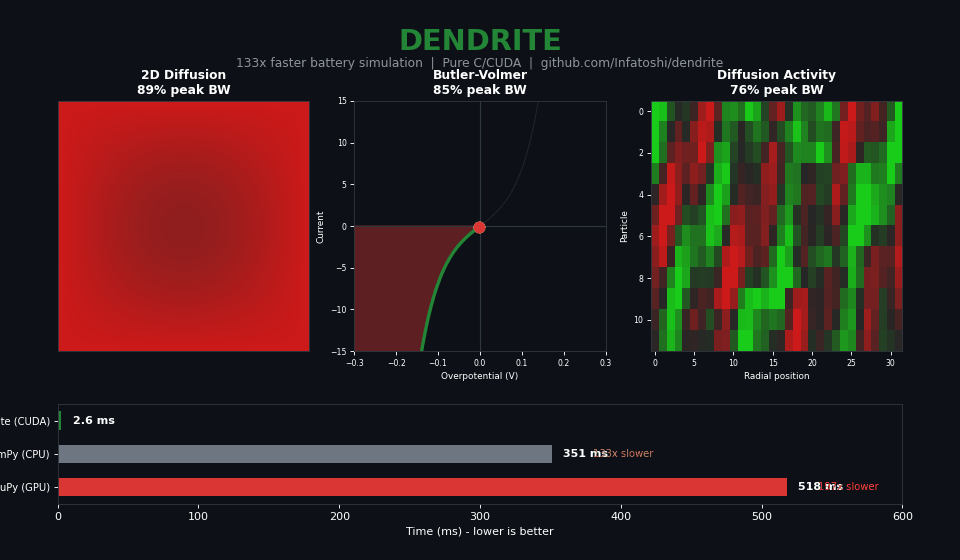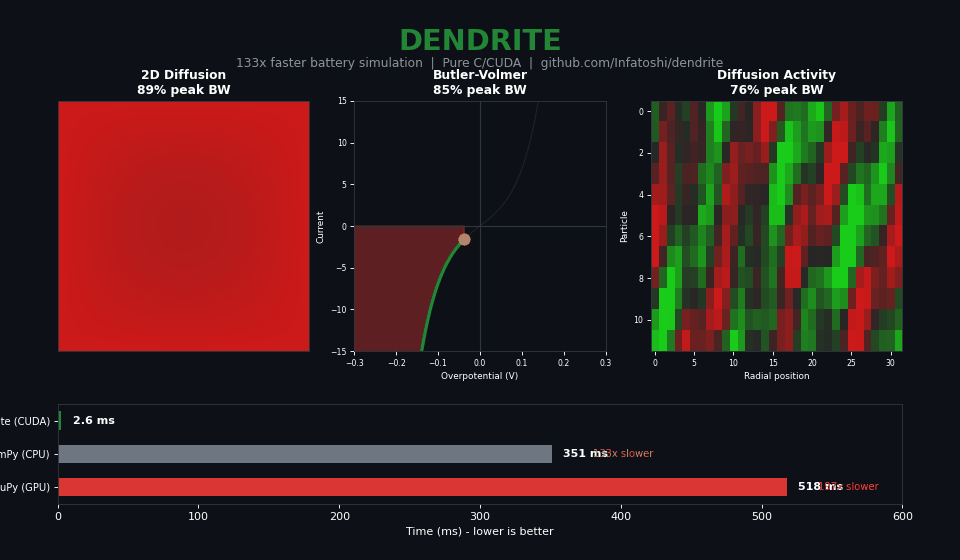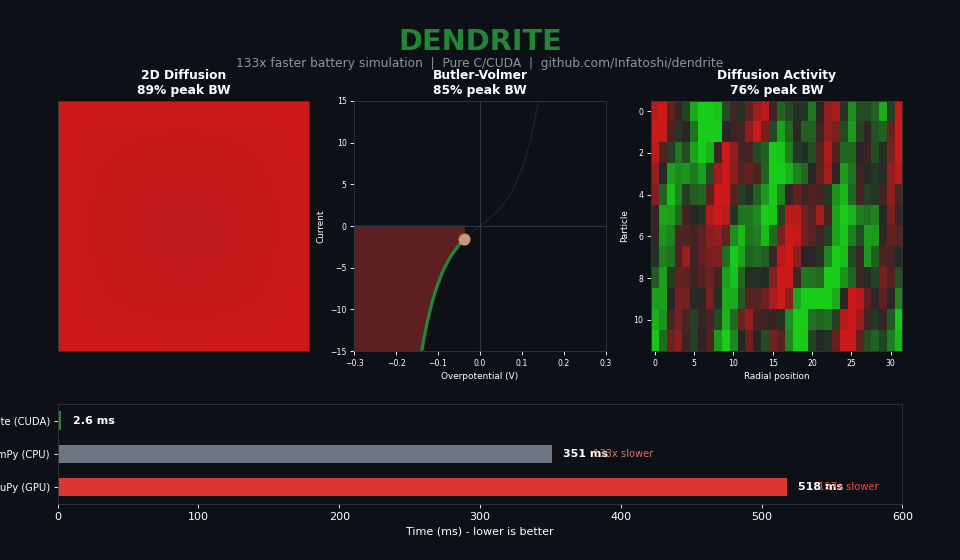
| PyBaMM IDAKLU (projected) | 35,744 ms | 13,490x slower |
| NumPy vectorized | 351 ms | 133x slower |
| CuPy vectorized (naive GPU) | 518 ms | 197x slower |
| Dendrite CUDA | 2.63 ms | baseline |
The PyBaMM comparison is unfair - it's an implicit DAE solver for coupled multi-physics, not batch explicit diffusion. The fair comparison is NumPy: 133x speedup.
Note that CuPy (naive GPU) is slower than CPU. This is the trap that keeps scientific computing on CPU.
Kernel Performance
RTX 3090, 936 GB/s theoretical peak:
| Kernel | Bandwidth | Peak % |
|---|---|---|
| 2D Diffusion (4096x4096) | 832 GB/s | 89% |
| Butler-Volmer (4M points) | 794 GB/s | 85% |
| Spherical Diffusion (100K particles) | 712 GB/s | 76% |
Lessons Learned
- Naive GPU ports can be slower than CPU. Kernel launch overhead dominates for small operations. Always benchmark against a good CPU baseline.
- Lower occupancy can be faster. For memory-bound kernels, fewer warps means more cache per warp. Profile different block sizes.
- Warp shuffles beat shared memory for warp-sized data. No sync overhead, no bank conflicts, just register-to-register transfer.
- Benchmark methodology matters. Async kernel launches will give you fantasy numbers. Sync after each kernel for real measurements.
- Stop optimizing at 85%+ of peak. Most tricks add overhead when you're already near the bandwidth ceiling.
The Gap is Real
Battery simulation tools haven't adopted GPU because naive ports don't work. COMSOL claims 2-5x with cuDSS - underwhelming compared to 133x with hand-tuned kernels.
The same pattern appears across scientific computing. General-purpose libraries (cuBLAS, cuDNN) are well-optimized. Domain-specific operations often aren't. The battery community has excellent physics models - they just need matching CUDA kernels.
Code
Dendrite is pure C/CUDA. No Python dependencies.
git clone https://github.com/Infatoshi/dendrite
cd dendrite
make # builds lib/libdendrite.a
make examples # builds demo programs
make benchmarks # builds benchmark suite
./bin/benchmark # run it- GitHub: github.com/Infatoshi/dendrite
- Requirements: CUDA Toolkit 11.0+, NVIDIA GPU
- Tested on: RTX 3090 (Ampere, SM 8.6)
February 2025